SCPC 2021 1차 대회가 7월 16일 오후 3시부터 24시간동안 진행되었다.
SCPC 대회와 관련된 정보는 https://research.samsung.com/scpc 에서 찾을 수 있다.
이 게시글에서는 해당 문제들의 풀이를 다룬다.
1. 친구들
문제를 요약하면, i 번 정점과 i+Di 번 정점을 연결 할 때, (1≤Di≤N, i+Di가 N을 넘으면 연결하지 않음), 연결 성분의 개수를 계산하는 문제이다. 그래프를 만들어주고 DFS와 같은 방법을 이용해서 연결 성분을 세어 주면 끝나는 문제이다.
이 문제에는 같은 시간복잡도의 좀 더 간단한 풀이가 있는데, i+Di가 N을 넘는 수의 개수가 답이 된다. 이를 증명하기 위해서는 다음과 같은 관찰이 필요하다.
- 이 그래프에는 사이클이 존재하지 않는다.
만약에 이 그래프에 사이클이 존재한다고 하자. 이 때, 이 사이클에 있는 정점중 가장 낮은 번호를 가진 정점은, 자기보다 번호가 큰 정점 두 개와 연결이 되어있다. 정점을 연결하는 규칙은 수가 작은 i 번 정점과 수가 큰 i+Di 번 정점을 연결하는 것이므로 작은 i 번 정점에 두 개의 연결이 있을 수 없어서 모순이다.
이런 관찰을 통해, 최초에 정점이 존재하지 않았던 상태에서 연결 성분의 개수가 N개이고, 한 번 연결할 때 마다 연결 성분의 개수가 1씩 줄어드므로, 답은 N - (i+Di가 N 이하인 수의 개수) = i+Di가 N 초과인 수의 개수이다.
2. 이진수
문제를 요약하면, 길이 N의 0과 1로 이루어진 문자열 B와 어떤 상수 T가 주어지는데, 0과 1로 이루어진 (숨겨진) 길이 N의 문자열 A에 대해서 Ai+T와 Ai-T중 1이 하나 이상 존재하는 경우에만 Bi가 1이 되도록 만들어진 문자열이다. 단, A의 i+T번째 문자나 i-T번째 문자가 존재하지 않는 경우에는 0으로 취급한다. 사전순으로 가장 빠른 A를 찾아서 출력하는 문제이다.
주어진 입력에 해당하는 A가 존재하는지 (문제에서 요구하지는 않았지만) 찾는 알고리즘을 생각하도록 하자.
- Bi-T나 Bi+T중 0이 있다면, Ai는 0이어야 한다.
만약 Ai가 1인 경우, Bi-T와 Bi+T가 (존재한다면) 1이어야 하기 때문에, 만약 이 두 수 중 0이 있으면, Ai는 0이어야 모순이 발생하지 않는다.
- Bi-T와 Bi+T중에 0이 없다면, Ai를 1로 두어도 "상관 없다." 여기서 "상관 없다"의 의미는, A가 만약에 존재한다면, Ai가 1인 답도 존재한다는 의미이다.
만약에 Ai가 0인 답이 존재한다고 하자. 이 Ai를 1로 바꾸게 되면, Bi-T와 Bi+T만 영향을 끼치고, 이 두 숫자는 이미 1이기 때문에, 해당하는 칸에도 영향을 끼치지 않는다. 그래서 Ai가 1이게 되는 답이 존재한다.
이 두 가지 사항을 이용해서, A가 존재하는지 찾는 알고리즘을 만들었으면, 사전순으로 가장 빠른 A를 찾는 알고리즘은, 가장 첫 자리가 0인 A가 존재하는지 확인하고, 존재한다면 가장 첫 자리를 0으로, 존재하지 않는다면 가장 첫 자리를 1로 설정한다. 마찬가지로 (첫 자리가 고정된 A에 대해) 둘째 자리가 0인 A가 존재하는지 확인하고, 존재한다면 가장 첫 자리를 0으로, 존재하지 않는다면 1로 설정한다, 이를 계속 반복하는 것이 문제의 풀이가 될 것이다. 여기까지의 알고리즘을 구현하면 O(N2) 시간 복잡도의 풀이를 얻을 수 있다.
이 알고리즘의 시간을 줄이는 법은, A가 존재하는지 확인하는 알고리즘은 Ai의 값 하나의 변경에 대해서는 작은 영향을 끼친다는 것을 관찰하는 것이다. 주어진 입력에 해당하는 최대의 A를 만들자. 그 후, 앞에서부터 살펴보면서, 1이 있으면 해당 1을 0으로 바꿀 수 있으면 바꾸는 과정을 반복하면 문제를 해결할 수 있다. (이는 Ai가 0인 A가 존재하는지 확인하고, 가능하면 0으로 설정하는 과정과 동일하다.) 1을 0으로 바꿀 수 있는지 여부는 Ai를 바꾸었을 때, B라는 문자열 전체, 특히 Bi-T와 Bi+T가 바뀌지 않을 것을 의미한다. 이를 위해서 추가적으로 Ai-2T와 Ai+2T 칸을 확인 해 줘야 한다. 이 과정을 구현하면 O(N) 시간 복잡도의 풀이를 얻을 수 있다.
3. No Cycle
문제를 요약하면, 그래프가 주어지는데 M개의 간선들은 방향성이 있고, K개의 간선들은 방향성이 없다. 이 때, 방향성이 없는 간선에 적당히 방향을 줘서 사이클이 없도록 해야한다. 단, 답이 여러개 존재하는 경우에 사전순으로 가장 빠른 답을 출력해야한다. 여기서 답은 길이 K의 0과 1로 이루어진 문자열인데, i 번째 방향성이 없는 간선은 두 개의 정점 쌍 (ui, vi)로 주어지며, ui→vi로 방향을 주면 답의 i번째 문자가 0이고, vi→ui로 방향을 주면 답의 i번째 문자가 1이다.
2번 문제와 유사한 종류의 관찰을 요구한다. 일단 답이 존재하는지 아닌지 찾는 알고리즘에 대해서 확인 해 보자. 방향이 주어진 M개의 간선에 대해서는 사이클이 없기 때문에 위상정렬을 실행할 수 있고, 해당 위상정렬에 대해 뒤쪽에 있는 간선을 앞쪽에 있는 간선으로 이어주면 항상 사이클이 없는 답을 찾을 수 있다.
사전순으로 가장 빠른 것을 찾는 알고리즘은 2번 문제에 설명된 대로 가장 첫 자리를 0인 답이 존재하는지 아닌지 확인하고, 존재한다면 0, 존재하지 않는다면 1로 설정한 뒤에, 둘째 자리에 대해서도, 셋째 자리에 대해서도 마찬가지로 같은 방법으로 문제를 해결하는 것이다. 이 문제에서는 이미 방향성이 주어진 간선이 사이클이 존재하지 않는 경우 항상 답이 존재하기 때문에, i 번째 자리를 정하고 있다면 i+1 번째 이후의 모든 간선을 무시하고, i번째 간선을 정방향으로 넣었을 때 지금까지 들어가있는 간선에 사이클이 존재하지 않는지 여부를 확인 해 주는 것으로 문제를 해결할 수 있다. 시간복잡도는 O(MK+K2)이다.
4. 예약시스템
문제를 요약하면, 사람이 2M명 있고 그룹이 N개 있다. 각 사람은 그룹 중 하나에 속해있으며, 스트레스 지수가 있다. 이 2M명의 사람을 2×M 모양의 방에 배치하려고 하는데, 그룹이 다른 두 사람이 인접한 방에 배치된 경우에는 충돌이 발생하고, 두 사람의 스트레스 지수의 합만큼 비용이 발생한다. 방에 사람을 적당히 배치해서 비용의 합을 최소화 하는 문제이다. 단, 같은 그룹끼리는 서로 연결되어 배치되어 있어야 하고, 한 그룹에는 5명 이상의 사람이 속해있다.
문제를 생각하기 용이하게 해주도록 배치의 비용을 다르게 나타내어 보자. 사람을 기준으로 생각했을 때, 해당 사람이 만드는 충돌의 개수는, 그 사람에게 인접한 다른 색을 가진 사람의 개수랑 같다. 그렇기 때문에, 총 비용은 모든 사람의 (해당 사람과 인접한 색이 다른 사람 수)×(해당 사람의 스트레스 지수)의 합이다.
이제 정답이 가질 수 있는 배치를 생각 해 보자, 첫번째로 2×M 모양에서 첫번째 열과 마지막 열은 특수하게 다루어져야 하는데, 그룹의 경계를 생각할 때 가장 왼쪽 혹은 가장 오른쪽 열은 그룹의 경계이지만 충돌이 발생하지는 않는다. 그렇기 때문에, 우리는 이 두 열에 대한 특수한 배치를 증명할 것이다.
- 첫번째 열과 마지막 열의 두 사람이 같은 그룹인 정답이 존재한다.
만약에 첫번째 열을 차지하는 두 그룹이 다른 사람인 정답이 존재한다고 하자. 이 둘은 크기가 더 작은 그룹이 존재한다. 해당 그룹을 A라고 하자. 모든 그룹은 연결되어야 하기 때문에, A는 일직선으로 존재하고 B도 A의 맞은 편 행에 일직선으로 존재하게 된다. (A가 끝난 이후에는 아무렇게나 존재할 수 있다.) 각 사람에 대해서 다음 그림과 같이 번호를 붙이자. (A3가 A의 가장 왼쪽 사람, A2, A1이 A의 가장 오른쪽 사람, A1의 오른쪽 사람이 C이고, B1, B2가 B의 가장 왼쪽 사람, B3가 A1의 맞은편 행에 있는 사람이다.)

여기서 연결관계가 바뀐 사람들의 비용차이를 계산 해 보자. 여기서 B와 C가 같은 그룹일 수 있음에 유의하여라.
* A1: 발생하는 충돌이 1개 줄었다. (B3, C → B2)
* A2: 발생하는 충돌이 1개 늘었다. (B1)
* A3: 발생하는 충돌이 1개 줄었다. (B1)
* B1: 발생하는 충돌이 1개 혹은 0개 늘었다. (A3 → A2, C)
* B2: 발생하는 충돌이 1개 줄었다. (A1)
* B3: 발생하는 충돌이 1개 줄었다. (B1)
* C: 발생하는 충돌이 1개 혹은 0개 줄었다. (B1)
바꿔서 코스트가 가장 커지는 경우는 발생하는 B1에서 발생하는 충돌이 1개 늘고, C에서 발생하는 충돌이 바뀌지 않는, B와 C가 다른 그룹인 경우이다. 이 경우를 상정하자.
최초 배치에서, A1은 충돌이 2개 발생하고, A2는 충돌이 1개 발생했다. 그렇기 때문에 위의 답이 최적이려면 A2의 스트레스 지수는 A1의 스트레스 지수보다 크거나 같아야 한다. 또한, B1과 B2는 모두 충돌이 1개 발생했기 때문에, B1의 스트레스 지수가 B2의 스트레스 지수보다 작거나 같은 답이 존재한다. 이런 사항을 고려해보면, A1과 B1에서 발생하는 비용의 증가는 A2와 B2에서 발생하는 충돌의 감소가 모두 해결해 줄 수 있고, 추가로 A3와 B3 혹은 C에서 발생하는 충돌의 감소가 스트레스 지수를 더 줄여준다. 그렇기 때문에, 첫번째 열과 마지막 열의 두 사람이 같은 그룹인 정답이 존재한다.
위와 같은 증명으로, 우리는 첫번째 열과 마지막 열의 두 그룹을 고정할 수 있다. 해당 그룹 전체에서 발생하는 스트레스 지수에 대해서 생각하자. 해당 그룹의 경계에서는 최소 두 명의 스트레스 지수가 발생한다. 홀수인 경우에는 (가장 작은 스트레스 지수)*2 + (2번째로 작은 스트레스 지수)가 되고, 짝수인 경우에는 (1, 2번째로 작은 스트레스 지수의 합)이 된다.
이제 해당 그룹이 아닌 내부에 존재하는 그룹에 대해서 생각하자.
- 해당 그룹이 두 열 이상에 대해 두 행의 방을 모두 차지하고 있는 경우. (2×2 방을 차지하고 있는 경우)
두 열을 기준으로 왼쪽과 오른쪽으로 분리하게 되고, 왼쪽 경계와 오른쪽 경계에 있는 사람들이 충돌하게 된다. 해당 경계에 두 사람만 존재하는 것이 가능하므로, 왼쪽 경계에 두 사람 오른쪽 경계에 두 사람이 존재하는 경우가 해당 그룹이 가질 수 있는 경계의 최솟값이다.
* 해당 그룹의 크기가 홀수일 경우, 한쪽 경계에는 두 행을 모두 차지하고, 다른쪽 경계에는 한 행만 차지하는 경우가 된다. (사진에 있는 2번째 그룹에 해당된다.) 이 경우, 경계에 스트레스 지수가 낮은 사람을 배치하면 해당 그룹의 스트레스 지수는 (가장 작은 스트레스 지수)*2 + (2, 3, 4번째로 작은 스트레스 지수의 합)이 된다.
* 해당 그룹의 크기가 짝수일 경우, 양쪽 경계에서 두 행을 모두 차지하는 것이 스트레스 지수의 최솟값이다. 이 경우 해당 그룹의 스트레스는 (1, 2, 3, 4번째로 작은 스트레스 지수의 합)이 된다.
* 해당 그룹의 크기가 짝수이지만, 양쪽에 와야하는 사람 수가 홀수라서 양쪽 경계에서 두 행을 모두 차지하지 못하는 경우가 있을 수 있다. 이 경우 그룹의 스트레스의 지수는 (1, 2번째로 작은 스트레스 지수의 합)*2 + (3, 4번째로 작은 스트레스 지수의 합)이다.

- 해당 그룹이 한 열 이하에 대해 두 행의 방을 모두 차지하고 있는 경우.
나머지 양 끝쪽에 존재하는 방에 대해서는, 충돌이 적어도 두 번 이상 일어나고, 칸 하나를 제외한 나머지 칸에 대해서도 충돌이 한 번 이상 일어나게 되기 때문에, 스트레스 지수의 합은 (1, 2번째로 작은 스트레스 지수의 합)*2 + (3, 4번째로 작은 스트레스 지수의 합) 이상이 되게 된다. 그러므로 해당 경우는 스트레스 지수가 위에 말한 경우보다 크게 된다.
이제 위와 같은 상황이 가능한 배치가 존재하는지 확인 해 보자. 홀수 그룹의 방을 항상 두 개씩 인접해서 배치하는 전략을 사용하면, 위에서 말한 모든 그룹의 스트레스 크기를 최소화하는 배치를 할 수 있다. 이렇지 못하는 경우는, 홀수 크기의 그룹이 정확히 2개이며 왼쪽 끝과 오른쪽 끝에 가야하는 경우이고, 이 경우에는 양쪽에 와야 하는 사람 수가 홀수인 짝수 크기 그룹과 같은 형태로 배치할 수 있다.
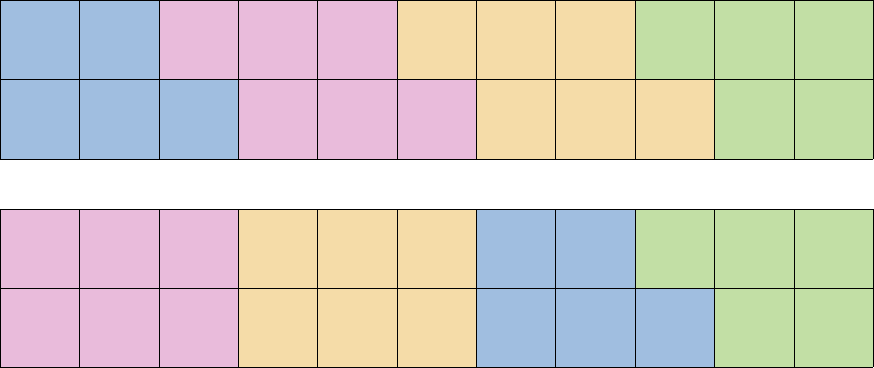
이 방법으로 오른쪽과 왼쪽 끝에 가야하는 그룹을 정하고, 나머지의 스트레스 지수를 더하는 방식을 사용하면 O(M3) 혹은 O(M2)의 시간복잡도가 발생하게 된다. 이제 이 과정을 최적화 하자.
홀수 크기의 그룹이 정확히 2개이며, 왼쪽 끝과 오른쪽 끝에 가야하는 경우를 제외하고는, 각 그룹의 스트레스 크기는 최소화 되기 때문에 총 비용은 (두 그룹을 제외한 각 그룹의 가운데에서 스트레스 지수) + (두 그룹의 양쪽 끝에서 스트레스 지수)이며, 이를 다시 쓰면, (모든 그룹의 가운데에서 스트레스 지수) - (두 그룹이 양쪽 끝에 왔을 때 줄어드는 스트레스 지수의 양)이 된다. 각 그룹의 양쪽 끝에 왔을 때 줄어드는 스트레스 지수의 양은 고정되어있기 때문에, 이 중 최댓값 두 개를 골라서 전체 스트레스 지수에서 빼주는 방식을 사용하면 총 O(N+M)의 시간복잡도를 얻을 수 있다.
문제의 조건 중에, 각 그룹끼리 연결될 것과, 그룹의 크기가 5이상일 것이라는 조건이 있다. 왜 이런 조건이 존재하는지는 다음과 같은 예제로 알아볼 수 있을 것 같다.

5. 차이
문제를 요약하면, 쿼리가 다음과 같이 두 종류 들어오고, 2번 종류 쿼리에 대해 답을 해야한다.
- 1번: i, j, v가 주어진다. 이는 Xi-Xj=v라는 정보를 의미한다.
- 2번: i, j가 주어진다. 지금까지 1번 쿼리로 들어온 정보들을 토대로 Xi-Xj의 값을 계산해야 한다. 여기서 계산이라고 함은 다음과 같은 과정으로만 재귀적으로 정의된다.
* Xi-Xj=v나 Xj-Xi=-v가 1번 쿼리로 주어졌다면, Xi-Xj=v라고 계산할 수 있다.
* Xi-Xj=v와 Xj-Xk=u라고 계산할 수 있으면, Xi-Xk=v+u라고 계산할 수 있다.
위의 과정을 (유한번) 재귀적으로 사용해서, Xi-Xj의 값을 계산할 수 있는지와, 계산할 수 있다면 계산 결과가 유일한지를 판단하여라. (1번으로 주어진 정보에 모순이 존재할 수도 있다.)
위와 같은 문제에서, Xi-Xj의 값을 계산할 수 있는지를 먼저 살펴보자. 계산에 관한 정보를 빼고 보면, 위의 설명은 i와 j가 연결되어있는지 아닌지에 관한 설명이다. 그렇기 때문에, 잘 알려진 Disjoint-set과 같은 알고리즘을 사용해서 문제를 해결할 수 있다.
이제, 값을 계산해 보자. Disjoint-set알고리즘은, 트리에서 자신의 부모 노드를 가지고 있는 알고리즘이다. 그렇기 때문에, 자신의 부모 노드와 자신과의 차이를 누적하면, 자신과 루트 노드의 차이를 알 수 있다. Disjoint-set알고리즘 상의 트리에서 노드 i의 부모가 p이고 루트가 r인 경우에, Xr-Xp는 재귀적으로 구할 수 있고, Xp-Xi는 Disjoint-set에서 자기 부모를 저장하는 배열에 자기 부모와 자기 자신의 차이를 추가적으로 저장해서 차이를 구할 수 있다. 2번 쿼리가 들어왔을 때, i와 j가 같은 연결성분에 들어있지 않다면, 값을 계산할 수 없다. 하지만 같은 연결성분 안에 있다면, Xr-Xi와 Xr-Xj를 계산해서 (Xr-Xj)-(Xr-Xi)이 답이 된다.
이제, 1번 쿼리를 생각해 보자. 하는 과정에서, 서로 다른 두 연결성분에 들어 있으면, 해당 두 연결성분을 Xi-Xj=v라는 관계로 추가로 연결 해 주면 된다. 하지만, 같은 연결성분에 들어있는 경우 계산 결과에 모순이 발생할 수 있다. 이 때는, Xi-Xj=v가 맞는지 2번 쿼리와 같은 방법으로 실제로 확인해 주고, 모순이 발생한 경우에는 해당 연결성분 전체에서 모순이 발생한다고 생각할 수 있다. i,j를 포함하는 Xi-Xj의 결과로 두 개 이상의 답이 존재하는 경우에는 같은 연결 성분에 속한 a, b에 대해서도 Xa-Xi + Xi-Xj + Xj-Xb = Xa-Xb의 결과가 두 개 이상이 된다. 그렇기 때문에 루트노드 쪽에 해당 연결성분에 모순이 발생하는지 아닌지를 체크해 주면 된다. 시간 복잡도는 Disjoint-set 알고리즘과 같은 O(Mα(M)) 이다.
아래는 문제에 대한 코드이다.
1번
#include <cstdio>
#include <vector>
using namespace std;
int solve(const vector<int>& V)
{
int N = (int)V.size();
int ans = 0;
for(int i=0; i<N; ++i)
if(i + V[i] >= N) ++ans;
return ans;
}
int main()
{
int T; scanf("%d", &T);
for(int t=1; t<=T; ++t)
{
int N; scanf("%d", &N);
vector<int> V(N);
for(int i=0; i<N; ++i) scanf("%d", &V[i]);
printf("Case #%d\n%d\n", t, solve(V));
fflush(stdout);
}
}
2번
#include <iostream>
#include <string>
#include <vector>
using namespace std;
string solve(int T, const string &B)
{
int N = (int)B.length();
string A(N, '1');
for(int i=0; i+T<N; ++i)
{
if(B[i+T] == '0') A[i] = '0';
if(B[i] == '0') A[i+T] = '0';
}
for(int i=0; i<N; ++i) if(A[i] == '1')
if(i-T < 0 || (i-2*T >= 0 && A[i-2*T] == '1'))
if(i+T >= N || (i+2*T < N && A[i+2*T] == '1'))
A[i] = '0';
return A;
}
int main()
{
int TC; cin >> TC;
for(int t=1; t<=TC; ++t)
{
int N, T; cin >> N >> T;
string B; cin >> B;
cout << "Case #" << t << '\n' << solve(T, B) << endl;
}
}
3번
#include <iostream>
#include <string>
#include <vector>
#include <utility>
using namespace std;
enum State {WHITE, BLACK, GRAY};
bool dfs(const vector<vector<int>>& conn, vector<State>& visit, int a)
{
if(visit[a] == BLACK) return false;
if(visit[a] == GRAY) return true;
visit[a] = GRAY;
for(int x: conn[a])
if(dfs(conn, visit, x))
return true;
visit[a] = BLACK;
return false;
}
bool hasCycle(const vector<vector<int>>& conn)
{
vector<State> visit(conn.size(), WHITE);
for(int i=0; i<(int)conn.size(); ++i)
if(dfs(conn, visit, i))
return true;
return false;
}
string solve(int N, vector<pair<int, int> > O, vector<pair<int, int> > U)
{
vector<vector<int> > conn(N);
for(auto [u, v]: O) conn[u-1].push_back(v-1);
string ans;
for(auto [u, v]: U)
{
--u; --v;
conn[u].push_back(v);
if(hasCycle(conn))
{
conn[u].pop_back();
conn[v].push_back(u);
ans += '1';
} else ans += '0';
}
return ans;
}
int main()
{
int T; cin >> T;
for(int t=1; t<=T; ++t)
{
int N, M, K; cin >> N >> M >> K;
vector<pair<int, int> > O, U;
for(int i=0; i<M; ++i)
{
int a, b; scanf("%d%d", &a, &b);
O.emplace_back(a, b);
}
for(int i=0; i<K; ++i)
{
int a, b; scanf("%d%d", &a, &b);
U.emplace_back(a, b);
}
cout << "Case #" << t << '\n' << solve(N, O, U) << endl;
}
}
4번
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
long long solve(vector<vector<int>> V)
{
vector<pair<int, int> > O; // stress, lift
vector<tuple<int, int, int> > E; // stress, lift, special
for(auto& x: V)
{
sort(x.begin(), x.end());
if(x.size()%2 == 0)
{
int stress = x[0] + x[1] + x[2] + x[3];
int lift = x[2] + x[3];
int special = x[0]*2 + x[1]*2 + x[2] + x[3];
E.emplace_back(stress, lift, special);
}
else
{
int stress = x[0]*2 + x[1] + x[2] + x[3];
int lift = x[2] + x[3];
O.emplace_back(stress, lift);
}
}
long long ans = 0;
if(O.size() != 2 || E.size() != 0) // handle normal case, careful not to include OE...EO
{
vector<int> lifts;
for(auto [st, li, sp]: E) lifts.push_back(li);
if(O.size() == 2) lifts.push_back(max(get<1>(O[0]),get<1>(O[1])));
else for(auto [st, li]: O) lifts.push_back(li);
sort(lifts.rbegin(), lifts.rend());
for(auto [st, li, sp]: E) ans += st;
for(auto [st, li]: O) ans += st;
ans -= lifts[0] + lifts[1];
}
if(O.size() == 2) // special case
{
long long spc = 0;
for(auto [st, li, sp]: E) spc += sp;
for(auto [st, li]: O) spc += st-li;
if(ans == 0) ans = spc;
else ans = min(ans, spc);
}
return ans;
}
int main()
{
int T; scanf("%d", &T);
for(int t=1; t<=T; ++t)
{
int N, M; scanf("%d%d", &N, &M);
vector<vector<int> >V(N);
for(int i=0; i<N; ++i)
{
int s; scanf("%d", &s);
V[i].resize(s);
for(int j=0; j<s; ++j) scanf("%d", &V[i][j]);
}
printf("Case #%d\n%lld\n", t, solve(V));
}
}
5번
#include <cstdio>
#include <vector>
using namespace std;
struct UFD
{
vector<pair<int, long long> > ufd;
explicit UFD(int N): ufd(N) {
for(int i=0; i<N; ++i) ufd[i] = {i, 0LL};
}
bool isValid(int x)
{
return ufd[Find(x).first].second == 0LL;
}
void setInvalid(int x)
{
ufd[Find(x).first].second = -1LL;
}
pair<int, long long> Find(int a)
{
auto [p, u] = ufd[a]; // x[p]-x[a] = u;
if(a == p) return {p, u};
auto [r, v] = Find(p); // x[r]-x[p] = v;
return ufd[a] = {r, u+v};
}
void Union(int a, int b, int t)
{
auto [pa, va] = Find(a); // x[pa]-x[a] = va
auto [pb, vb] = Find(b); // x[pb]-x[b] = vb
if(!isValid(a) || !isValid(b))
{
ufd[pb].first = pa; setInvalid(pa);
}
else if(pa == pb)
{
if(vb-va != t) setInvalid(pa);
}
else ufd[pb] = {pa, va-vb+t};
}
enum Cases {No, Yes, Any};
pair<Cases, long long> diff(int a, int b)
{
auto [pa, va] = Find(a); // x[pa]-x[a] = va
auto [pb, vb] = Find(b); // x[pb]-x[b] = vb
if(pa != pb) return {Any, 0LL};
else if(!isValid(a)) return {No, 0LL};
else return {Yes, vb-va}; // vb-va = (x[p]-x[b])-(x[p]-x[a]) = x[a]-x[b]
}
};
void solve()
{
int N, Q; scanf("%d%d", &N, &Q);
UFD ufd(N);
while(Q--)
{
int c; scanf("%d", &c);
if(c == 1)
{
int u, v, t; scanf("%d%d%d", &u, &v, &t);
ufd.Union(u-1, v-1, t);
}
else
{
int u, v; scanf("%d%d", &u, &v);
auto [res, val] = ufd.diff(u-1, v-1);
if(res == ufd.No) puts("CF");
else if(res == ufd.Any) puts("NC");
else printf("%lld\n", val);
}
}
return;
}
int main()
{
int T; scanf("%d", &T);
for(int i=1; i<=T; ++i)
{
printf("Case #%d\n", i);
solve();
}
}'프로그래밍 > 알고리즘' 카테고리의 다른 글
| SCPC 2022 본선 풀이 (0) | 2022.09.03 |
|---|---|
| SCPC 2022 2차 풀이 (0) | 2022.08.06 |
| SCPC 2021 2차 풀이 (0) | 2021.08.07 |
| 테스트 데이터 만들기: Anti-Hash test / Anti-Javasort test (0) | 2018.10.11 |
| Simple Cubic General Maximum Matching Algorithm (0) | 2018.03.22 |